Data Center Tier Classification: Engineering for Reliability and Uptime

In today’s data-driven operations, data center infrastructure must be engineered to specific uptime expectations that reflect business-critical workloads. The Uptime Institute Tier Classification System is a globally recognized framework used to benchmark these expectations against facility topology and operational resilience.
Understanding how each Tier level is defined, certified, and sustained is crucial for engineers responsible for designing and managing resilient data center infrastructure. This article provides a technically comprehensive look at Tier levels, operational practices, failure risk models, and the practical trade-offs between redundancy and cost.
The Uptime Institute Tier System: Engineering Definitions
The Tier classification is topology-based, meaning it reflects the physical infrastructure design—particularly power, cooling, and distribution paths—that determines a facility’s fault tolerance and maintainability.
Only the Uptime Institute can perform official Tier certifications. The use of terms like “Tier III+” or “Tier 3.5” are marketing artifacts and have no technical or certification validity.
Key Concepts:
Single Point of Failure (SPOF): A component or path whose failure would interrupt IT service delivery.
Concurrent Maintainability: Ability to maintain/reconfigure systems without IT downtime.
Fault Tolerance: Ability to withstand a failure without impacting critical load.
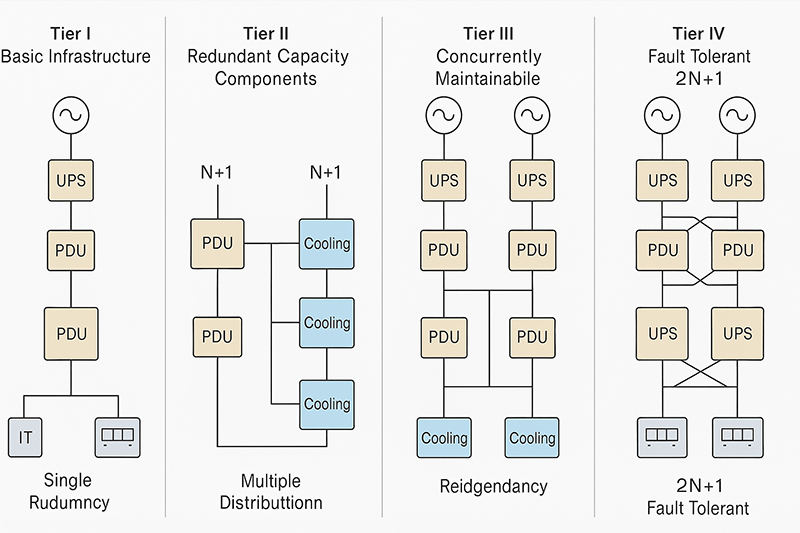
Tier-by-Tier Technical Breakdown
Tier I: Basic Infrastructure
Power & Cooling: Single distribution path, no redundant components.
Risk: Any failure in UPS, chiller, PDU, or switchgear results in an outage.
No maintenance window: All maintenance must be done offline.
Use case: Labs, development environments, or non-critical departmental servers.
Availability: 99.671% (28.8 hours/year downtime)
Tier II: Redundant Capacity Components
Adds N+1 redundancy to capacity components (UPS, chillers, pumps).
Still only one path for power and cooling distribution.
Systems must be taken offline for maintenance.
Redundancy is at the component level, not the system level.
Availability: 99.741% (22 hours/year downtime)
Tier III: Concurrently Maintainable
Dual distribution paths (power + cooling), only one active at a time.
No single point of failure in active systems.
Maintenance or replacement of any component possible without IT load impact.
Requires sophisticated switchgear (STSs), A+B power paths, and segregated cooling.
Availability: 99.982% (1.6 hours/year downtime)
Tier IV: Fault Tolerant Infrastructure
2N (or 2N+1) fully independent, simultaneously active power paths.
Any failure in a path (power outage, equipment failure, pipe burst) is absorbed without impact.
Includes distributed redundant chillers, isolated electrical paths, and automated failover systems.
Often includes diverse fuel sources, automated generator controls, and dynamic load shedding.
Availability: 99.995% (26.3 minutes/year downtime)
Certification: Design vs. Constructed Facility
1. Tier Certification of Design Documents (TCDD):
Validates the engineering intent.
Requires full design documentation (one-line diagrams, capacity plans, cooling topologies).
Issued before construction begins.
2. Tier Certification of Constructed Facility (TCCF):
Confirms the facility was built and commissioned according to certified design.
Requires functional testing under live or simulated loads.
Involves failure injection testing (e.g., power path failure during peak load).
3. Operational Sustainability (OS):
Often overlooked, but essential.
Evaluates management, maintenance, and risk practices that ensure sustained uptime.
Poor operational discipline can erode Tier benefits regardless of infrastructure.
Operational Factors: Beyond Design
Even a certified Tier IV facility can underperform if operational processes don’t meet high reliability standards. Key areas include:
Maintenance Planning:
Use of maintenance bypass panels, live swap systems, hot standby units.
Incident Response:
Clear runbooks, alarm thresholds, escalation procedures.
Environmental Monitoring:
Multi-point temperature and humidity sensing (rack inlet/outlet, CRAC supply/return).
DCIM integration with predictive analytics.
Root Cause Analysis:
RFO documentation, system logs, historical sensor trends.
Risk Modeling and Failure Domains
Each Tier addresses risk differently:
Tier I/II: Failure domains are entire system-level (e.g., UPS or chiller goes down = downtime).
Tier III: Failure domains are component-level, with maintenance isolation.
Tier IV: Failure domains are system-wide, but with full redundancy and instant failover.
Engineers should model fault tree analyses (FTA) and mean time between failure (MTBF) assumptions per Tier level when designing systems.
Conclusion
Data center engineers must view the Uptime Institute’s Tier system not just as a design checklist, but as an ongoing commitment to infrastructure integrity, operational excellence, and risk mitigation. Proper alignment of Tier selection with business needs—and sustaining it through certified design, construction, and operations—is the key to delivering reliable digital services.